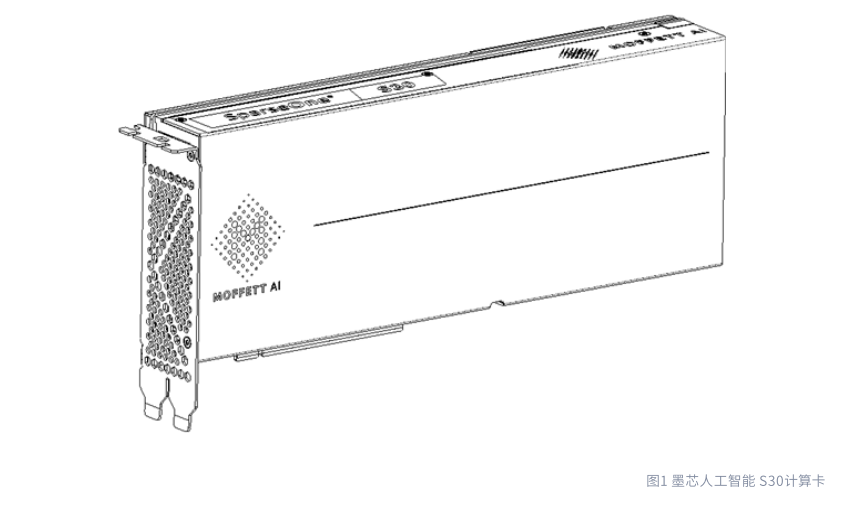
墨芯 S30 AI 计算卡产品手册
概述
墨芯人工智能 S30 计算卡(下文简称 S30 计算卡)为数据中心的 AI 推理应用而打造。作为通用深度学习推理加速器,外形规格采用双槽 PCle Gen4 x16 的全高全长的设计方式。S30 计算卡支持 60 GB LPDDR4x 内存,高达 185 GB/s 峰值内存写带宽和 185 GB/s 峰值内存读带宽,最大功耗 250 W。被动冷却板设计使其在热限制内,通过系统气流来实现计算卡的操作。
S30 计算卡基于墨芯人工智能 Antoum® 架构构建。通过软硬件紧密结合的架构设计,强调平衡的结构化稀疏性,支持高达 32 倍的高稀疏率。基于 Antoum® 架构,S30 计算卡支持 FP16/BF16 和 INT8 计算。同时,S30 计算卡支持包括集成模型稀疏器的软件工具链、编译器和运行时在内的端到端软件解决方案,确保主流 AI 推理作业可以快速实现。
硬件与软件紧密结合的设计使得 Antoum® 成为一个高效的人工智能片上系统处理器。此外,S30 计算卡还支持硬件视频编解码器和 JPEG 解码器,使其能够处理各种视频和图像应用场景。同时,S30 计算卡随设备发货时,为系统 DDR 开启 ECC 功能,防止内存出现可检测的错误。
规格
产品规格
| 规格 | 描述 |
|---|---|
| 产品名称 | SparseOne®疏云®AI 计算卡系列|墨芯人工智能 S30 计算卡 |
| TDP | 250 W |
| Antoum®️芯片名称 | 墨芯 Antoum®英腾®芯片 |
| 机械外形规格 | 双槽,全高全长 |
| PCI IDs | Device ID: 0x7030 Vendor ID: 0x1F36 Sub-vendor ID: 0x1F36 Sub-system ID: 0x7000 |
| VBIOS NOR-Flash 大小 | 16 MB |
| 热冷却解决方案 | 被动式 |
| 系统接口 | PCIe Gen 4 x16 |
| 板卡重量 | 1584.4 g |
| P2P 带宽 | P2P 单边带宽:26.38GB/s P2P双边带宽:52.76GB/s |
| Idle Power | 40 W |
内存规格
| 规格 | 描述 |
|---|---|
| 最大内存时钟 | 4200 MHz |
| 内存大小 | 60 GB |
| 内存总线宽度 | 480-bit |
| 理论峰值内存带宽 | 峰值内存写带宽 185 GB/s 峰值内存读带宽 185 GB/s |
环境和可靠性规格
| 规格 | 描述 |
|---|---|
| 操作环境温度 | 0℃ - 50℃ |
| 存储温度 | -40℃ - 70℃ |
| 操作环境湿度 | 5%~95% 相对湿度 |
| 存储湿度 | 5%~95% 相对湿度 |
| 降频温度 | 90 ℃ |
| 停止工作温度 | 100℃ |
| 下电温度 | 110℃ |
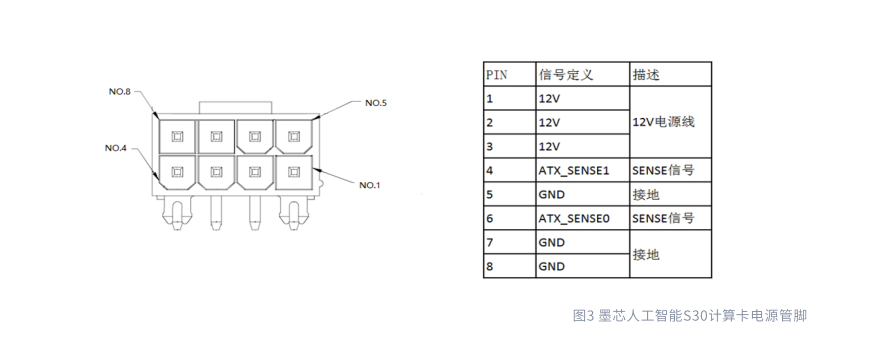
电源示意图和管脚定义
接口名称
PCIe 8-Pin Power Connector
电源位置示意图

电源管脚定义
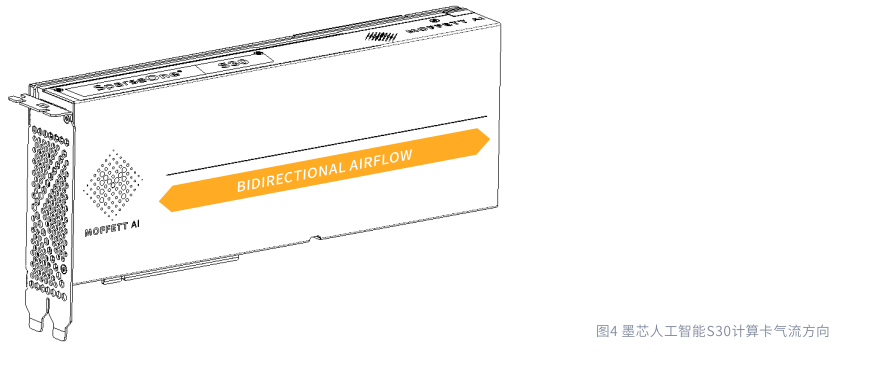
气流方向的支持
S30 计算卡采用双向散热的设计,实现灵活散热。它可以接受从左到右或者从右到左的气流,如下图所示。
产品功能
PCIe 接口规格
S30 计算卡的接口规格如下所述:
PCIe 速率支持
S30 计算卡支持 PCIe Gen 4.0
PN 翻转和 Lane 翻转支持
S30 计算卡支持 PCIe 规范中定义的 PN 翻转和 Lane 翻转。当翻转 PCIe 通道时,Rx 通道和 Tx 通道的顺序都必须颠倒。
硬件信任根
S30 计算卡通过片上硬件安全引擎和 ARM CPU 信任区域技术支持硬件根信任。信任根的基本功能包括安全引导和安全固件升级。S30 计算卡可以通过加密和认证进一步保护用户的 AI 模型,由强大的密钥管理系统和硬件信任根支持。
多实例 SPU 支持
S30 计算卡支持最多 12 个多实例 SPU(稀疏处理单元)。墨芯人工智能 MIS (Multi-Instance SPU) 技术可以将 S30 计算卡划分为多个单个实例,每个实例与自己的 DDR、片上存储器、AI 计算核心、视频编解码器和 JPEG 解码器完全隔离,从而实现计算资源供应和服务质量的优化。
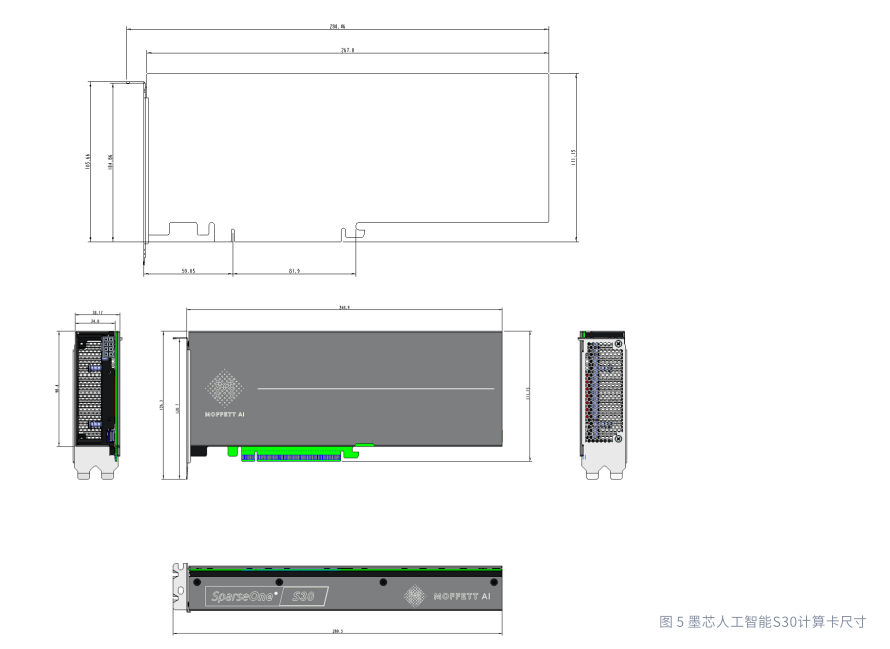
外形规格
S30 计算卡采取全高全长双槽的设计,标称尺寸如下图所示。